

In this article, I provide a brief explanation of advanced DNA sequencing technologies.
DNA Sequencing
The process of determining the order of nucleotides in DNA is called DNA sequencing. It determines the order of the four bases, i.e., adenine, guanine, thymine, and cytosine. The nucleotide sequence is the basis for understanding a gene or genome, as it contains the instructions for building an organism. DNA sequencing is used to determine the sequence of individual genes, clusters of genes, full chromosomes, or the entire genome of any organism.
The development of two techniques in 1977 made possible the sequencing of larger DNA molecules. The first-generation sequencing technology determines DNA sequences of several kb in length, using the chain termination method and the chemical degradation method. F. Sanger and A.R. Coulson in the UK first developed the chain termination method. The chemical degradation method was introduced by the American molecular biologists A. Maxam and W. Gilbert. Although both techniques followed similar strategic principles, Sanger’s method, known as the dideoxy chain-termination sequencing, was technically simpler and ultimately became the foundation for most modern sequencing technologies. Over the years, the methods for sequencing DNA have evolved rapidly, moving from slow, manual techniques to highly advanced, automated systems that can sequence entire genomes in hours.

Automated Sanger Sequencing
DNA sequencing was first automated by a variation of the Sanger method. In the 1980s, Sanger’s method was transformed through automation. Fluorescent dyes replace radioactive labeling. Time-consuming gel electrophoresis gave way to capillary electrophoresis systems (Figure 1). With this technology, all four ddNTPs could be introduced into a single reaction. Researchers could sequence DNA molecules containing thousands of nucleotides in a few hours. These innovations allowed machines to read DNA sequences with higher accuracy and speed, laying the groundwork for large-scale projects like the Human Genome Project. A complete human genome can now be sequenced within two days, whereas a bacterial genome can be sequenced in a few hours.

While some sequencing strategies share similarities with the Sanger method, others differ significantly. These advanced approaches involve multiple steps. First, the genomic DNA is randomly fragmented into smaller pieces, each a few hundred base pairs long. Short, synthetic DNA sequences of known composition are then attached to both ends of these fragments, serving as reference points.
The fragments are subsequently fixed onto a solid surface and amplified in place using PCR, creating dense clusters of identical DNA molecules. This solid surface is part of a flow cell, a narrow channel designed to allow liquid reagents to move across the samples. As a result, millions of distinct DNA clusters, each originating from a single genomic fragment, are distributed across an area just a few centimeters wide. The power of next-generation sequencing lies in its ability to sequence all these clusters simultaneously, with the resulting data from each cluster captured and stored digitally for analysis.
Next Generation Pyrosequencing
One next-generation method, known as 454 sequencing, uses a technique called pyrosequencing. This approach detects the incorporation of nucleotides by measuring light signals generated during the reaction. The four natural (unaltered) dNTPs are flowed over the surface one at a time in a repeating cycle. Each nucleotide remains on the surface briefly, allowing DNA polymerase to incorporate it into any DNA cluster where it is complementary to the template. When a nucleotide is added, a light-emitting chemical reaction occurs, and the intensity of the flash corresponds to the number of nucleotides added, allowing the sequence to be determined.
The Procedure
Any excess nucleotide is rapidly degraded by the enzyme apyrase before the next nucleotide is introduced. When a nucleotide is successfully incorporated into a DNA strand, pyrophosphate (PPi) is released as a byproduct (Figure 2). The enzyme sulfurylase uses this pyrophosphate to convert adenosine 5′-phosphosulfate (APS) into ATP. The generation of ATP then triggers the enzyme luciferase to catalyze a reaction with luciferin, producing a tiny flash of light (Figure 2). These flashes indicate successful nucleotide incorporation. When many such events occur within a cluster, the emitted light is strong enough to be recorded as a digital image, allowing the sequence to be determined.

When dCTP is added to the solution, light flashes occur only in clusters where the next base in the template is G, allowing C to be incorporated into the growing strand. If the template contains a stretch of two, three, or more G residues in a row, an equal number of C nucleotides is added in that single cycle. This results in a flash amplitude that is proportionally two, three, or four times stronger than that of a single nucleotide incorporation, enabling the system to estimate how many nucleotides were added. Similarly, when dGTP is introduced, flashes are detected in a different set of clusters, where C is the next base in the template. The number of nucleotides that can be reliably sequenced in a single run is known as the read length. It typically ranges from 400 to 500 bases, though this is continually improving with advancements in technology.
Advantages of Pyrosequencing
454 pyrosequencing marked a significant advancement in the development of next-generation sequencing technologies. It offered comparatively longer read lengths and relied on light-based detection to monitor nucleotide incorporation, making it effective for sequencing small genomes and specific DNA targets. However, the method struggled with accurately reading homopolymer regions—sequences with repeating identical bases—and was relatively costly per base. These drawbacks led to the emergence of newer, more efficient platforms like reversible terminator sequencing (Illumina sequencing). This soon became the preferred choice for large-scale and high-throughput sequencing projects.
Reversible Terminator Sequencing (Illumina sequencing)
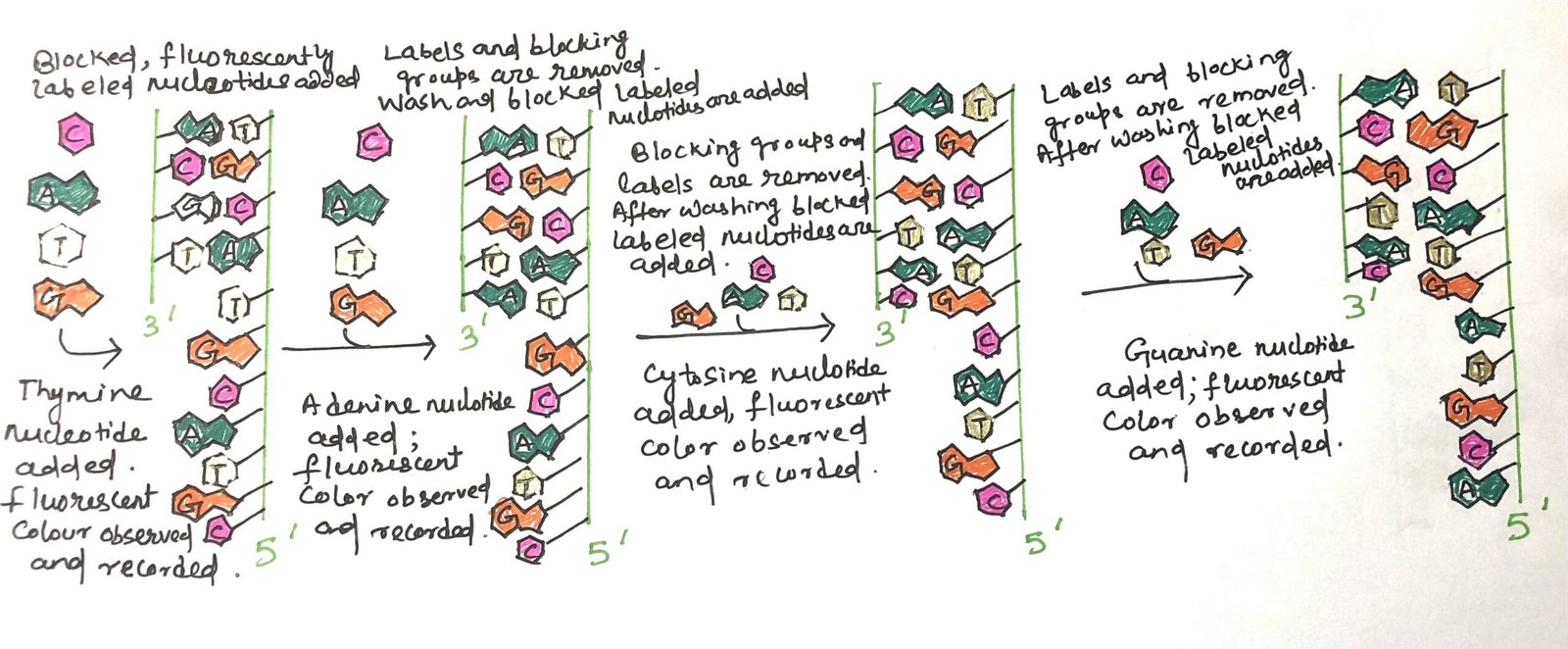
Illumina sequencing, also referred to as reversible terminator sequencing (Figure 3), is among the most commonly used technologies in next-generation sequencing (NGS). This technique involves the use of chemically modified nucleotides, each tagged with a unique fluorescent marker and a temporary blocking group that prevents further DNA synthesis. In each cycle, a single nucleotide is incorporated, detected through imaging, and then chemically unblocked to allow the next base to be added. This process repeats across millions of DNA fragments fixed on a flow cell, enabling the simultaneous sequencing of vast numbers of DNA strands with high accuracy, efficiency, and scalability.

The genomic DNA is first fragmented, and short oligonucleotides of known sequence (adapters) are ligated to both ends of each fragment. These modified fragments are then immobilized on a solid surface and amplified in place by PCR, forming clusters of identical DNA molecules. A sequencing primer, complementary to the adapter sequence, is added to initiate the sequencing process. Next, four specially modified reversible terminator nucleotides, A, T, G, and C, each tagged with a distinct fluorescent dye, are introduced along with DNA polymerase. Due to the presence of 3′-end blocking groups, only one nucleotide is incorporated at a time into each growing strand. After incorporation, lasers excite the fluorescent tags. Thus, the emitted light is captured as an image, revealing the identity of the base added to each cluster by its color.
How Advanced Sequencing Enhances Genome Accuracy and Insight
Advancements in sequencing technologies have significantly accelerated and reduced the cost of determining an organism’s entire genomic sequence. This process involves translating millions of short DNA reads into a complete and organized genome using computational methods that align overlapping sequences. The average number of times a specific nucleotide is read during sequencing is known as sequencing depth. Typically, genomes are sequenced in such a way that each nucleotide is read approximately 30 to 40 times. Although the actual coverage for individual nucleotides can vary, this level of depth generally ensures that most bases are sequenced at least 10 times, which helps identify and correct sequencing errors.
The overlapping nature of these short fragments enables software to follow the sequence along the chromosome, assembling them into long, continuous segments known as contigs. In successful sequencing projects, some contigs may span millions of base pairs.
Deep Sequencing
Deep sequencing refers to increasing the sequencing depth to 100x or even 1000x by analyzing a much larger quantity of DNA. This method is particularly useful for detecting mutations or genomic variations present in only a fraction of an organism’s cells. Deep sequencing is also critical for studying the genetic makeup of cancer cells, which often have unstable and rapidly changing genomes as tumors evolve.
Emerging Technologies in DNA Sequencing
DNA sequencing technologies continue to evolve at a rapid pace. These advancements are driven by the need for faster, more accurate, and cost-effective ways to decode entire genomes. Newer methods not only improve read lengths and error detection but also allow sequencing of complex genomic regions that were previously difficult to analyze. As a result, they are increasingly being applied in clinical diagnostics, cancer genomics, and metagenomics studies, among other fields.
Ion-Semiconductor Sequencing
This method utilizes immobilized DNA fragments, similar to the approach used in 454 and Illumina sequencing. In this method, the four deoxynucleotide triphosphates (dNTPs) are introduced sequentially in a repeating cycle, with each one being removed before the next is added. When a specific dNTP is incorporated into the growing DNA strand, protons are released as a byproduct of the reaction, and these are detected to identify the nucleotide added.
Single-Molecule Real Time (SMRT) Sequencing
The development of highly sensitive light-detection systems enables single-molecule real-time (SMRT) sequencing. In SMRT sequencing, a single DNA polymerase molecule is immobilized at the base of each of millions of nanoscopic wells on a flow cell. Genomic DNA fragments diffuse into these wells, where the polymerase captures them. Labeled dNTPs also diffuse in, and as each nucleotide is incorporated into the DNA strand, it releases a fluorescent tag. This light flash is recorded by a detection system, revealing the identity of the added base. SMRT sequencing is known for its accuracy and its ability to produce long read lengths, often up to 10,000 base pairs.
Together, these cutting-edge technologies continue to push the boundaries of genomic research, enabling scientists to explore genetic information with unprecedented detail and speed.
Conclusion
The process of determining the order of nucleotides in DNA is called DNA sequencing. It is used to determine the sequence of individual genes, clusters of genes, full chromosomes, or the entire genome of any organism.
One next-generation method, known as 454 sequencing, uses a technique called pyrosequencing. This approach detects the incorporation of nucleotides by measuring light signals generated during the reaction. 454 pyrosequencing marked a significant advancement in the development of next-generation sequencing technologies. It offered comparatively longer read lengths and relied on light-based detection to monitor nucleotide incorporation, making it effective for sequencing small genomes and specific DNA targets.
Illumina sequencing, also referred to as reversible terminator sequencing, is among the most commonly used technologies in next-generation sequencing (NGS). This technique involves the use of chemically modified nucleotides, each tagged with a unique fluorescent marker and a temporary blocking group that prevents further DNA synthesis.

Deep sequencing refers to sequencing a genomic region at a very high depth, often 100x or more, to detect rare mutations or variants present in a small fraction of cells. It is particularly useful in studying heterogeneous samples, such as cancer tissues with unstable and rapidly changing genomes.
Ion semiconductor sequencing detects the incorporation of nucleotides by measuring the release of protons during DNA synthesis. It introduces one type of nucleotide at a time and relies on changes in pH to identify which base has been added. SMRT sequencing uses a highly sensitive light-detection system to monitor the addition of fluorescently labeled nucleotides by a single DNA polymerase in real time. It enables long read lengths—often up to 10,000 base pairs, and provides high accuracy for complex genomic regions.
You may also like:
- DNA Beyond the Double Helix: Structural Variants and Unusual Sequences
- Southern Blotting: Detection of Specific DNA Sequence

I, Swagatika Sahu (author of this website), have done my master’s in Biotechnology. I have around fourteen years of experience in writing and believe that writing is a great way to share knowledge. I hope the articles on the website will help users in enhancing their intellect in Biotechnology.